Match Amplified:
A live AI career platform that handles the full job-search workflow: discovery to tailored documents. Built solo on n8n + Supabase as an AI agentic system.
Match Amplified is a live AI career platform at matchamplified.com. It handles the full job-search workflow, from discovery through tailored document generation, in one integrated system. It is built for mid-career white-collar professionals between jobs, who lose months and thousands of euros in revenue to a structurally broken process. As of early March 2026 it is fully functional, pre-revenue and building toward payments and multi-source job search.
Table of contents
Open Table of contents
1. Context: why I built this
In January 2026 I joined The Product Compass Buildathon, where I worked on a first iteration of Match Amplified, called back then NextStep. I was in the middle of my own career transition at the time, so the problem space was not abstract: it was personal. With a small team we shipped a working prototype in a few weeks. After the buildathon ended I refactored the codebase, expanded the scope and rebranded the product as Match Amplified. The conviction: this is too real a problem to leave as a hackathon artifact.
2. The problem
2a. The pain
The numbers are bleak. The average job search runs 3 to 6 months and 120 to 400+ hours of manual effort. 70 to 90% of applications get rejected. For mid-level roles, in-between-job transitions cost candidates €10 to 25k+ in lost income. The psychological toll (uncertainty, repetition, low signal from the market) compounds the financial one.
2b. Market opportunity and gaps
The macro setup favors solving this now: ATS systems are getting more sophisticated, remote work is expanding the option set and economic uncertainty is driving more frequent transitions.
The market is sizable:
- TAM ≈ €1.65B/year (EU, ~22M job seekers × ~€75/search);
- SAM ≈ €792M (white-collar professionals, ~8.8M × ~€90/search);
- SOM at 0.5% capture by Year 3 lands around €4M ARR.
The competitive landscape is fragmented:
| Category | Examples | What they do well | What they leave on the table |
|---|---|---|---|
| Job boards | LinkedIn, Indeed | Massive listings, employer reach; basic application tracking; some AI document adaptation in premium tiers | Tracking is rudimentary; AI features are siloed and feature-driven, not workflow-integrated; no end-to-end ownership |
| CV builders | Zety, Resume.io | Templates, visual design | Generic output, not job-specific |
| ATS optimizers | Jobscan | Keyword matching | Manual copy-paste, no generation |
| Application trackers | Huntr, Teal | Organization, pipeline visibility | No discovery, no document generation |
| Career coaches | TopResume | Personalized advice | €100 to 500+, slow, not scalable |
| Mass-appliers | LazyApply, Sonara | Volume automation | Spray-and-pray, irrelevant matches, chronically 0 interviews |
These gaps surface directly in user reviews of existing tools: generic AI output, technical glitches, no transparency, 0 interviews from 50 to 80 applications.
2c. Who it is for
Primary: in-between-jobs professionals. Mid-career white-collar workers actively looking for a new role. The category also catches active seekers who still hold a role but feel high urgency (strong dissatisfaction, restructuring news, deadline pressure): same job-to-be-done, similar willingness to pay. They run high volume (10 to 50+ applications per week), feel high urgency and have €5 to 15k+ recoverable income, making €15 to 40/month an easy value calculation.
Secondary: passive seekers. Satisfied in their current role, open to strong opportunities, want occasional high-relevance signals without noise. Active seekers in stable roles without urgency also fall here: they care about quality of suggestions, not volume.
Jobs to be done for the primary persona:
- Surface high-fit jobs: focus time on roles with the best chance of success.
- Generate customized CVs and cover letters without rewriting from scratch.
- Track application statuses centrally.
- Learn from feedback and improve over time.
- Maintain control and approval over automation. No black-box submissions.
Explicit non-personas: freelancers and contractors (V1 out of scope); junior mass-volume applicators (spray-and-pray is exactly what we are not).
3. The solution
3a. What we built

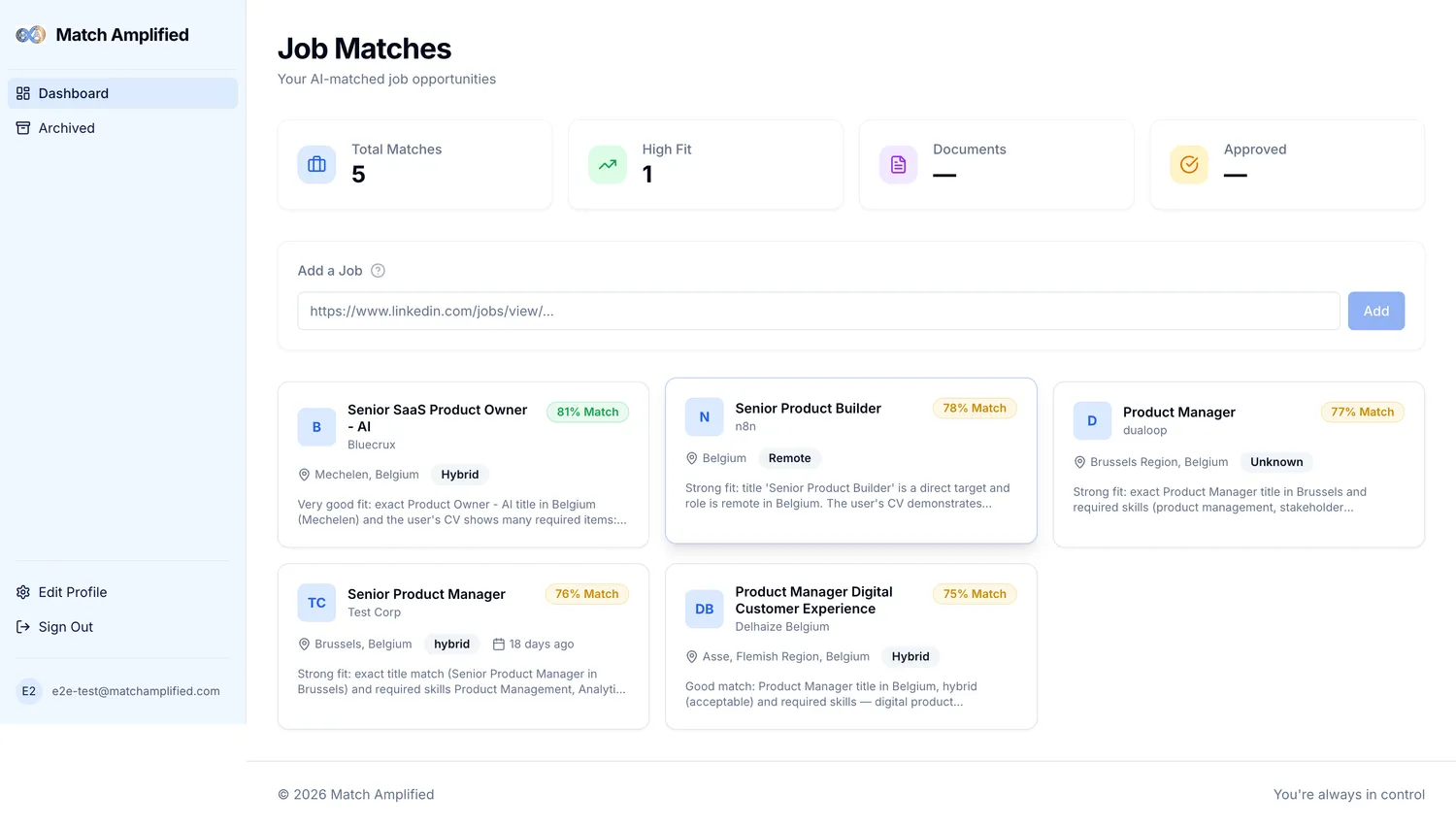
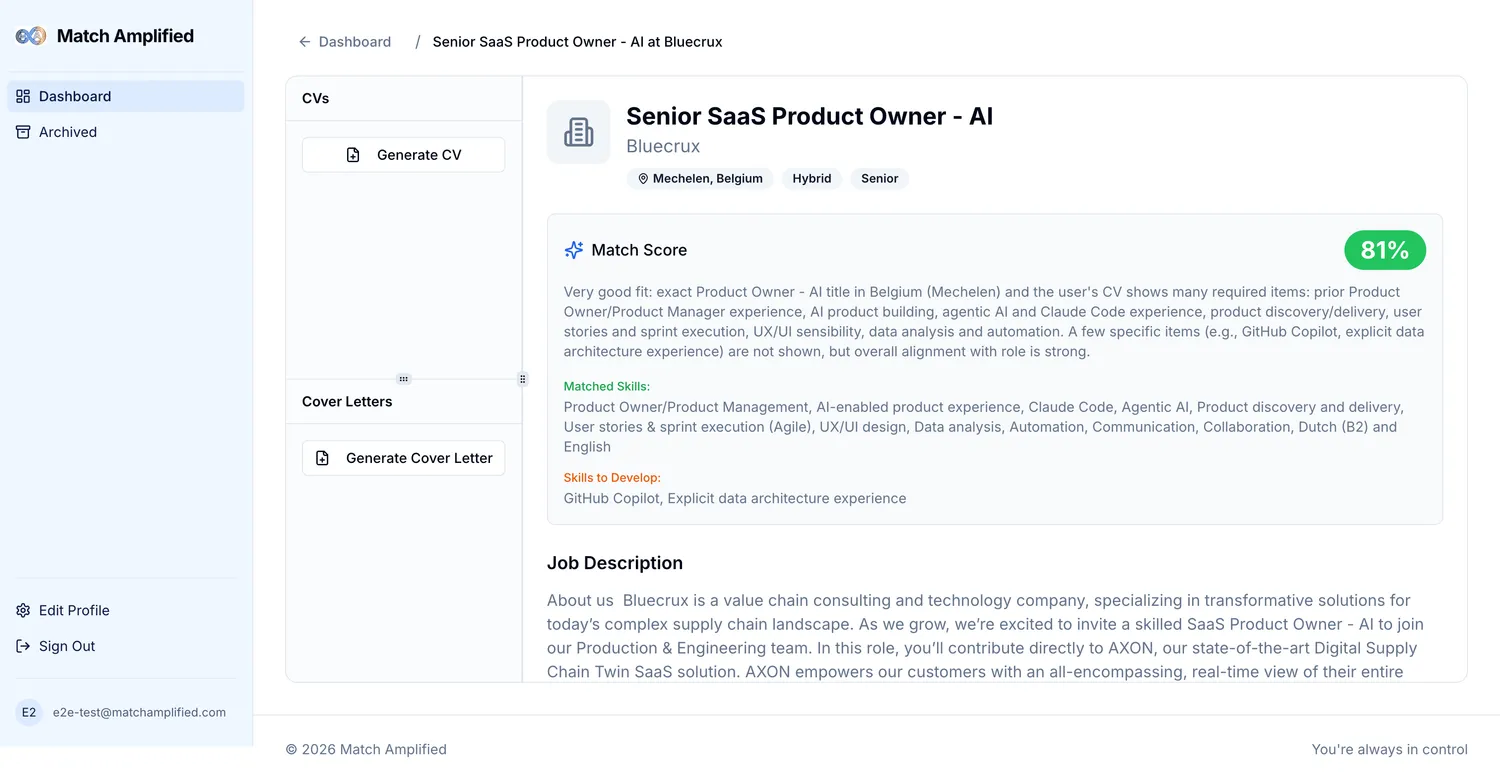
- Intelligent job matching: semantic weighted scoring, not keyword matching. Each match comes with a transparent rationale: skills matched, skills missing, why the score is what it is. Fit-score threshold is user-configurable.
- Job URL submission: paste any job posting URL; the system scrapes it, parses with an LLM, scores it against the profile and generates tailored documents in one flow.
- CV and cover letter generation: RAG-grounded from the user’s baseline CV (the more complete and well-structured the baseline, the better the tailoring), with a <1% hallucination design target. Documents flow through Markdown: easy in-app editing, version-able and easier for the AI agents to process than rich text or PDF. The user edits inline and approves to export a polished PDF.
- Adaptive style learning (the Adapter Agent): observes approved documents and user edits to learn tone, formality and structure preferences, with a ±5% max weight change per cycle to avoid overcorrecting.
- 4-step onboarding: upload CV (auto-parsed for skills and experience), confirm details, set search criteria, see first matches.
- Background automation: the Matcher runs every morning to surface fresh scored matches; the Adapter runs nightly to refine learned style preferences. Users open the app to ready-to-review opportunities, no manual triggering needed.
- Standard product surface: real-time dashboard, profile management, standard authentication (sign-in / sign-up / password reset), archived matches view.
- Match dashboard
- Match score breakdown
3b. Why this approach, not alternatives
- Not just a job board: we own the workflow after discovery, not just the listings.
- Not just a CV builder: job-specific, ATS-optimized generation, not templates.
- Not just an ATS optimizer: generation and optimization are integrated, not a separate copy-paste step.
- Not a mass-applier: the bet is quality over quantity. Fewer, better-fit applications with higher interview conversion.
The north-star metric is interview conversion rate (interviews per 100 applications; needs user input), not application volume.
3c. Differentiation and moats
- Learning flywheel. Competitors run static systems. Match Amplified builds a proprietary understanding of why profiles succeed.
- Short-term, it improves with every approved document and user edit.
- Long-term, it improves with every successful CV that lands an interview, as outcome data feeds back into matching and generation.
- Outcome ownership. We sell interviews and faster placement, not features. Transparent scoring rationale means users understand why a job matches.
- Workflow gravity. Once users onboard their baseline CV, the system learns their voice and keeps evolving with every edit they make. Switching costs increase as style preferences and match patterns accumulate.
- Human-in-the-loop, always. The system never applies to jobs automatically. Users review, edit and approve every document before it goes anywhere.
3d. Design principles and guardrails
- RAG-grounded generation. All AI outputs anchor to retrieved, user-approved data (baseline CV, job posting, application history). <1% hallucination is a design target: guardrails and evals are planned, the full evaluation infrastructure is not yet implemented.
- Explainability is non-negotiable. The system never presents an AI decision without surfacing why. The principle drives downstream design choices: score rationale, version history, edit logs.
- GDPR-mindful data minimization. Collect only what the workflow requires; treat user data as user-owned by default. Full export and deletion controls are roadmap commitments, not yet shipped.
- Latency <2s for core actions. Anything that takes longer runs asynchronously; the UI stays responsive.
- Observability. All AI decisions are logged for monitoring, auditing and continuous improvement.
4. Under the hood (high level)
Match Amplified is built as an agentic system on n8n + Supabase. A small set of specialized AI agents (a Matcher that scores opportunities, a Composer that generates tailored documents and an Adapter that learns the user’s style). Previous on the Buildathon project (NextStep), all this was coordinated by an orchestrator (the direct user chat interfaced with the orchestrator). All data reads and writes go through a centralized DataLayer for consistency and access control.
Why agents in the first place: semantic job matching, grounded document generation and adaptive style learning all need natural-language reasoning that classic deterministic code cannot reach.
For the deep dive on agent boundaries, autonomy levels, data flow and key build decisions, see Match Amplified: the agentic architecture under the hood.
5. Results and current state
Live at matchamplified.com since early March 2026, currently positioned publicly as an alpha, almost beta state. The end-to-end journey works: signup → onboarding (instant first matches within minutes) → daily fresh matches → URL submission → CV/CL generation → PDF approval. (PDF generation is backed by a third-party service on a free tier today; this will be upgraded as paying users join.) PostHog runs analytics in the background, cookie-less and GDPR-mindful.
Pre-revenue: no paying users yet. Payments integration is the next priority.
Honest gaps today: single job source (Adzuna only); no payments yet; the Adapter learning loop is limited to high-level preferences (granular in-text edits not yet wired); the on-premises LLM option is not implemented yet.
6. Lessons and what is next
Lessons:
- Infrastructure pivots are expensive in the short term but can compound into better architecture choices.
- Setting the human-in-the-loop constraint early shaped every downstream design decision. Non-negotiables should be set as design choices before writing code.
- TDD discipline is non-optional when building with AI coding agents and when output quality has direct user consequences.
- Tooling matters. Moving from Lovable to Claude Code mid-build gave more control, better output and the ability to build a proper CI/CD pipeline with tests included.
What is next:
- Payments integration for subscription validation. Paying users mean real intent, distinct from the prior validation rounds with non-paying users.
- Multi-source job search (LinkedIn, Indeed, Glassdoor; currently Adzuna only).
- Deeper personalization. The Adapter already learns from approvals, rejections and high-level preferences. Next step: closing the loop on granular in-text edits, so every application gets sharper and more authentically the user’s voice.
- On-premises, privacy-first LLM. Today’s models are cloud-hosted. Next step: a self-hosted option so user CVs and personal data never leave our infrastructure: full AI capability, full data sovereignty.
- Longer-term: become the system of record for job transitions. The intelligence layer that learns from every search, document and outcome.
Article series on Match Amplified
| # | Topic | JRM Lab | |
|---|---|---|---|
| 1 | The Buildathon and what came after | Buildathon intro on LinkedIn | From the Buildathon to Match Amplified |
| 2 | The agentic AI architecture | Agentic architecture on LinkedIn | Match Amplified: the agentic architecture under the hood |
| 3 | Lovable → Claude Code transition | Lovable to Claude Code on LinkedIn | From Lovable to Claude Code |
| 4 | VPS and infrastructure setup | Infrastructure setup on LinkedIn | Match Amplified: VPS and infrastructure |
| 5 | What’s already built in Match Amplified | What’s built on LinkedIn | Match Amplified: what’s already built |
| 6 | The roadmap | Roadmap on LinkedIn | Match Amplified: the roadmap |
| 7 | The naming process | Naming process on LinkedIn | Match Amplified: choosing the name |
| 8 | Where this all goes from here | What’s next on LinkedIn | Match Amplified: what’s next |
| Try it live: | matchamplified.com |
| Product Compass AI Gallery: | Match Amplified entry |
| Full case study: | Match Amplified product case study |