From the Buildathon to Match Amplified
- Jesús Rojo Martínez
- 06 May, 2026
Table of contents
Open Table of contents
Context: The Buildathon
I’m writing about the Buildathon a bit late. Intentionally. I wanted to share what came after, not just what happened during.
Back in January 2026, I joined the AI Agents Buildathon: six weeks of product managers building real AI agent systems, organised by Pawel Huryn from The Product Compass and Olia Herbelin. Pawel later posted on LinkedIn that 42 teams shipped. The bar wasn’t “build a prototype.” The bar was “build a real, working multi-agent system with well-defined autonomy boundaries and a coherent product solving an actual problem.”
That framing alone changed how I thought about AI agents. Most “AI agent” content online is either hand-wavy (“imagine an autonomous agent that…”) or one-shot demos. The Buildathon forced you to ship something with edges: what the agent does, what it doesn’t, what happens when it fails.
This article is about that experience and what came after. There’s a parallel LinkedIn series running alongside it (linked below); here I have room to go a bit deeper.
What we built: NextStep
Together with Pierre Ortega and Giovanni De Luca, two product managers I’d never worked with before the cohort, we built NextStep: a multi-agent system for job search.
The idea wasn’t novel. Job search is a saturated space. What we wanted to test was whether an agentic approach (multiple specialised agents coordinating, each with bounded autonomy) could meaningfully reduce the friction that makes job hunting so brutal: the manual tailoring, the keyword optimising, the application-and-pray loop.
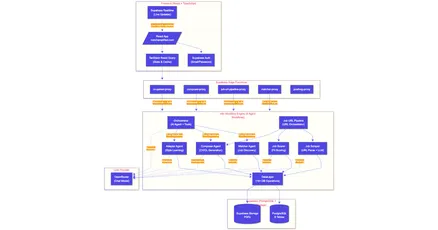
The system had four core agents:
- A Matcher that scored job postings against a user’s profile using a semantic weighted scoring algorithm. Full autonomy over discovery, zero autonomy over action.
- A Composer that generated tailored CVs and cover letters, RAG-grounded from the user’s baseline CV. Required explicit human approval before generating a PDF.
- An Adapter that learned from user edits over time, adjusting tone and style preferences in small, conservative increments.
- An Orchestrator that routed user input to the right agent based on intent (NextStep-only — that’s where users entered the system through a chat interface).
Underneath all of it sat a DataLayer: an abstraction layer that owned every database read and write. No agent touched the database directly, and every agent had to conform to the data contracts. That decision is what made debugging tractable. Without it, multi-agent systems become a tangle of inconsistent state.
We earned a certificate from The Product Compass for what we built. I’m proud of that, not because of the certificate itself, but because of what it stood for: a working system, built to a real spec, shipped end-to-end in six weeks.

Why those technology choices?
Three big ones: n8n for backend and orchestration, Lovable for the frontend, Supabase for data.
n8n for the agent orchestration. n8n was the backbone of the Buildathon thanks to its visual orchestration and how quickly you can put an AI Agent together. When you’re building four interacting agents under time pressure, being able to see the flow at a glance changes everything. You can trace data through the system without reading code. You can demo by pointing at the canvas. And n8n is self-hostable, which mattered for both the buildathon environment and longer-term ownership.
Lovable for the frontend. I’d used Lovable before for small personal projects (a winding-down routine app, a budget tool with receipt OCR), but never for something this scoped. We needed auth, onboarding, a job dashboard, document review screens and a marketing site, all in weeks. Lovable’s speed at scaffolding was the deciding factor. The constraint we had to accept: when you push it past simple flows, you start hitting limits. Debugging is opaque, and state coherence drifts on big edits. I’d planned to address this by exporting to GitHub once Lovable had done its scaffolding job. That plan worked.
Supabase as the data layer. PostgreSQL with built-in auth, storage, a clean SDK and a generous free-tier. We had originally picked Google Sheets to keep things simple. Then the Google account got fully blocked for rate-limiting and Supabase became the obvious move at that point.
On autonomy boundaries: the part that’s harder than it sounds
This is where the Buildathon framing showed its value. Most multi-agent demos online don’t take autonomy seriously. They define vague “guardrails” in a system prompt and call it done. That’s not what the Buildathon expected, and it’s not what we wanted to build.
We used Pawel’s Intent Engineering framework to structure each agent’s intent: objective, desired outcomes, health metrics, decision authority, soft guardrails (steering the agent’s reasoning) and hard guardrails (enforced rules the LLM cannot override). This work lived in full PRDs before a single workflow node was built.
What that meant in practice:
- The Matcher could discover and score jobs autonomously, but it could never apply on a user’s behalf. That’s a hard guardrail, enforced in the orchestration layer, not in a prompt.
- The Composer could generate as many drafts as it liked, but no document became a PDF without an explicit user approval click. Hard guardrail.
- The Adapter could shift style preferences, but only in ±5% increments and only after at least three approved documents existed. Conservative bounds, enforced in code.
It’s slower than letting the LLM do whatever. It’s also the right design for an agent that touches someone’s professional identity.
I’ll be honest about something: we defined these boundaries carefully, but we didn’t fully enforce all of them in code by the end of the buildathon. Some lived as design intent rather than runtime constraints. That gap was one of the things I started on after the buildathon ended, and I’m still working on them.
Then the Buildathon ended. And I kept going.
While most other teams stop here, I wanted to keep building. For two reasons:
- First, the system was close to genuinely useful, and the gap between “demo-good” and “real-user-good” was smaller than I expected.
- Second, I wanted to learn the parts of building that the Buildathon necessarily glossed over: infrastructure ownership, real iteration loops, brand and naming, deployment.
The transition wasn’t dramatic, but it was concrete. Several things had to change:
-
Codebase ownership. The Buildathon used shared infrastructure (provided by Pawel). I migrated everything to my own VPS (Hetzner), set up Coolify for self-hosted deployment and stood up a GitHub-to-production pipeline. That alone taught me more about ops than years of using managed platforms.
-
Lovable → Claude Code. Once the frontend was scaffolded, I switched to iterating directly on the codebase via Claude Code. Same tool philosophy (AI-assisted), but with full visibility into what was being generated and why. Later moved to VS Code with the Claude Code extension, which made running multiple parallel sessions much easier.
-
Frontend rebuild. Marketing site, dashboard, document review screens. All of these were reworked with proper polish.
-
A new name. NextStep was a fine name for the Buildathon, but it didn’t hold long: too many other products already use it. After collision-checking, some SEO research and a lot of sitting with options, the project became Match Amplified. (Article 7 in the series, links below, covers the naming process in full.)
The result is live: matchamplified.com.
It’s still in beta, still a side project. But it’s a working, end-to-end product, built solo, with AI tools throughout, on a stack I genuinely understand.
What’s next
There is a series of articles with companion LinkedIn posts. Eight posts in order, each with a deeper companion piece on JRM Lab as it goes live. The full index is below.
If any of that resonates, and especially if you’re a PM wondering whether you can actually build AI systems rather than just spec them, Pawel and Olia are running the next cohort: the Claudathon (this time not for free). I’d genuinely recommend it. The structure, the community and the accountability are what got me to ship something I’m now choosing to keep building.
A genuine thank you to Pawel Huryn, Olia Herbelin and the whole Product Compass community for creating something that pushed so many of us to ship real things.
More soon, both here and on LinkedIn.
Article series on Match Amplified
| # | Topic | JRM Lab | |
|---|---|---|---|
| 1 | The Buildathon and what came after | Buildathon intro on LinkedIn | this article |
| 2 | The agentic AI architecture | Agentic architecture on LinkedIn | Match Amplified: the agentic architecture under the hood |
| 3 | Lovable → Claude Code transition | Lovable to Claude Code on LinkedIn | From Lovable to Claude Code |
| 4 | VPS and infrastructure setup | Infrastructure setup on LinkedIn | Match Amplified: VPS and infrastructure |
| 5 | What’s already built in Match Amplified | What’s built on LinkedIn | Match Amplified: what’s already built |
| 6 | The roadmap | Roadmap on LinkedIn | Match Amplified: the roadmap |
| 7 | The naming process | Naming process on LinkedIn | Match Amplified: choosing the name |
| 8 | Where this all goes from here | What’s next on LinkedIn | Match Amplified: what’s next |
| Try it live: | matchamplified.com |
| Product Compass AI Gallery: | Match Amplified entry |
| Full case study: | Match Amplified product case study |